Les bases de données du Llacan
Les bases de données sont des outils de recherche très prisés car en organisant les données de façon structurée, elles permettent le filtrage, par exemple pour isoler un échantillon particulier, ou bien la recherche plus ou moins complexe dans ces données et la quantification des résultats. En voici quelques illustrations au LLACAN.
Bases de données outillage
Les chercheurs du laboratoire LLACAN (Langage, langues et cultures d'Afrique), sont des linguistes attachés à la description des langues d'Afrique, plus spécifiquement des langues peu décrites. Dès le début de l'accès aux ordinateurs personnels, dans les années 80, les chercheurs ont été confrontés à la difficulté de gérer leurs données textuelles avec les logiciels de traitement de texte. L'encodage des caractères étant alors limité à 256 codes, ils avaient du mal à saisir des données nécessitant des caractères non-latins, comme les caractères de l'alphabet phonétique international (API).
Cette situation qui dura plus de 15 ans a conduit à la création de nombreuses polices de caractères qui permettaient d'afficher ces caractères 'exotiques', ainsi que des astuces pour étendre les capacités du clavier pour saisir facilement ces caractères. Avec l'avènement du codage universel Unicode, suivi d'une lente progression vers sa prise en charge par les logiciels de saisie et de traitement des données, cette difficulté n'est plus d'actualité, mais il restait à gérer les anciennes données des chercheurs.
Une base de données des polices de caractères créées au LLACAN, montrant la distribution des caractères spéciaux sur les 256 codes des polices anciennes, permet d'assurer le transcodage des données anciennes lorsqu'elles ont besoin d'être ré-exploitées.

Par ailleurs, un travail de mise en base de données des systèmes phonologiques et alphabets de 200 langues africaines, issu de l'ouvrage Alphabets des langues africaines édité par Rhonda L. Hartell en 1993, permet également de visualiser dans l'espace phonétique traditionnel des consonnes et des voyelles, les sons de chacune de ces langues, ainsi que les caractères utilisés pour les transcrire dans l'orthographe officielle (de l'époque). On peut ainsi faire des inventaires de phonèmes ou de graphèmes, par langue d'un même groupe linguistique, ou par pays, ou bien rechercher les langues utilisant un même groupe de phonèmes ou de graphèmes.

Base de données pour le comparatisme
Certains travaux de recherche en comparatisme ont occasionné la création de bases de données sur des sujets assez spécifiques, comme le lexique comparatif historique des langues Sara-Bongo-Baguirmiennes ou les marques personnelles dans les langues africaines. Ces bases de données permettent de concentrer dans un espace organisé l'information autrefois disséminée dans de multiples ouvrages. Des filtrages et des recherches permettent ensuite, par exemple, de comparer la dissémination d'une forme ou d'une fonction à travers l'espace géographique de l'Afrique.

Comparatisme lexical
En capitalisant sur ces différentes approches, l'idée de concevoir un projet plus ambitieux qui regrouperait les différentes fonctionnalités de ces outils spécifiques dans une grande base de données lexicales, a pris corps avec la création du projet RefLex qui concentre dans une même base de données toutes les ressources lexicales connus (publiées ou grises) sur les langues africaines. Plus d'un million d'entrées sont à ce jour accessibles, en lien avec les documents PDF dont elles sont issues. La traçabilité des données est en effet une spécificité de cet outil car il permet de contrôler les sources (l'accès aux sources est réservé aux utilisateurs enregistrés pour éviter les indélicatesses).
Sur la base de ces ressources lexicales, différents modules permettent de faire du comparatisme en sélectionnant des sources par aires géographiques, ou linguistiques, sur lesquelles l'utilisateur va pouvoir travailler. Il pourra par exemple rechercher des cognats, c'est-à-dire des lexèmes qui ont potentiellement une même origine, en recherchant tous les mots correspondant à une même glose (par exemple cheval). L'utilisateur pourra alors en comparant (par alignement) les phonèmes composants les mots de son dataset, proposer des correspondances entre sons d'une langue à l'autre. L'utilisateur enregistré peut ainsi travailler dans son espace alloué, sur le domaine qui l'intéresse, et enrichir le travail de repérage des correspondances des sons d'une langue à l'autre qui permettra d'inférer des hypothèses de parenté entre langues.
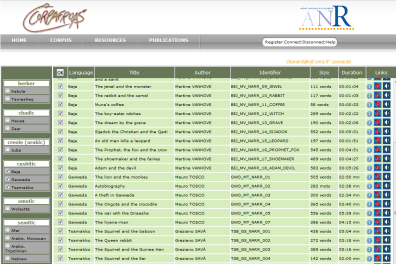
Corpus Oraux
Les programmes de recherche (CorpAfroAs, Sénélangues, CorTypo, CorMand…) autour de la description linguistique conduisent également à la création de bases de données textuelles issues de l'oral. Des enregistrements audio dans les différentes langues étudiées par les membres d'un projet sont archivés, et leurs transcriptions, traductions et annotations morpho-syntaxiques sont ingérées dans une base de données accessible en ligne. Ces textes peuvent ainsi être affichés et écoutés par l'utilisateur, qui pourra également faire des recherches sur la base des annotations, à travers un ensemble prédéterminé de ressources.
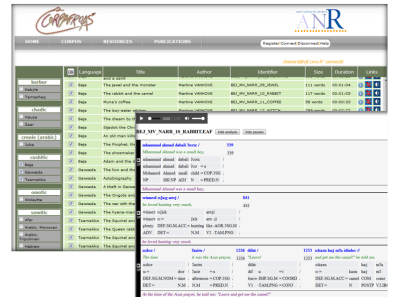
Les chercheurs utilisent également des outils de gestions de données lexicales grâce auxquels ils élaborent des dictionnaires au fil des années de recherche.
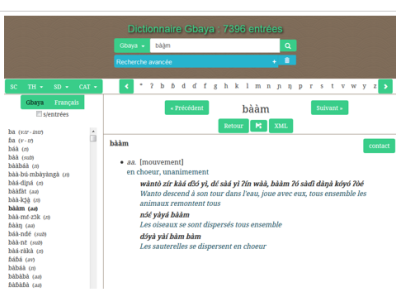
Les bases de données sont devenues des outils indispensables pour la recherche et leur mise en accès libre ou partagé sur l’internet permet de diffuser les produits de la recherche au LLACAN ainsi que les moyens d'analyse et de validation des données.
Christian Chanard
Responsable du pôle informatique du LLACAN